-
 Simple and Best
Simple and Best
-


机器的智力
近年来,人工智能迅速发展,最初目的是为了给机械、软件赋予类似人类智能的能力,从简单计算,逐渐演变到能够支持人类的复杂决策,或者解决一些创造性的问题。
经过新基建设施的不断升级建造,5G大面积的铺开等措施,算力有了大幅度的提升,算法也有了创新,也变成了如今我们了解到的ChatGPT、文心一言等。
大规模语言模型
大规模语言模型则是通过海量数据训练得到的模型。基于开源的生态,同时拥有海量的参数,通过预训练和微调来适应使用者,做出相应的产出。
但大语言模型也有很多疑问:
是否要独立开发?成本几何?
获得信息是否可靠?是需要的信息吗?
单个模型能够获得尽可能多需要的信息吗?
在当前瞬息万变的现实世界中,模型能否实时反应或进步?
投入能否匹配产出?
大语言模型固然有多任务学习能力并不断进化的优势,但投入巨大、见效缓慢、精度不高甚至答非所问也是不可否认的缺点。
随着研究的不断深入和技术的发展,高性能的小模型逐渐崭露头角,它们以小巧的体积实现了令人瞩目的性能,甚至在某些任务上超越了大型模型。
安邦政府大数据信息库正是一个典型的小语言模型,在政策分析领域展现了独特的优势。作为多年来深受用户重视的小语言模型,在政策分析研究中具有重要的应用潜力。
基于现有数据库分析系统平台基础上,衍生推出的一类个性化信息系统服务,是日常工作与研究的一种针对性数字化解决方案。旨在快速响应满足客户个性化信息服务所需。
安邦政府大数据信息库
安邦政府大数据信息库主要提供两类服务:
一、“数据库平台-内容运营”服务
二、“个性化-专属”数据库服务
那么,安邦政府大数据信息库,有哪些独特的优势?
精:精准匹配用户需求
同样的内容输入ChatGPT和安邦政府大数据信息库:
ChatGPT:

ChatGPT等大语言模型很难做到精准匹配,同时需要检验内容的真实性
安邦政府大数据信息库:
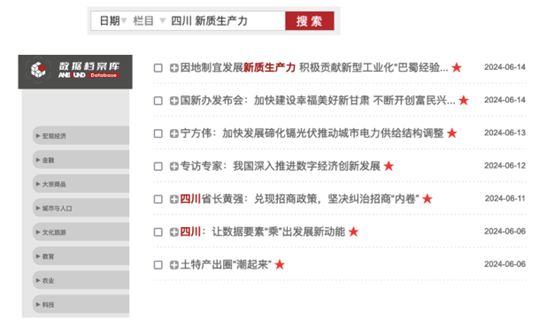
安邦政府大数据信息库能够做到精准匹配内容
通过整合多方面的公共开源数据,包括政府公开数据、学术研究、行业报告等,对小道消息、内部消息say no,确保数据的权威性和可靠性。
并通过不断更新和校准,保持数据的最新性和准确性,帮助用户获得最真实、最及时的信息。
细:细致入微,直指关键
政策分析中,细节往往决定成败。数据库能够捕捉关键点,深入挖掘数据中的细微差异,为用户提供详尽的分析报告,提供细分的行业、地区,多层次、多维度的精细信息,从而做出更精准的决策。
安邦政府大数据信息库:
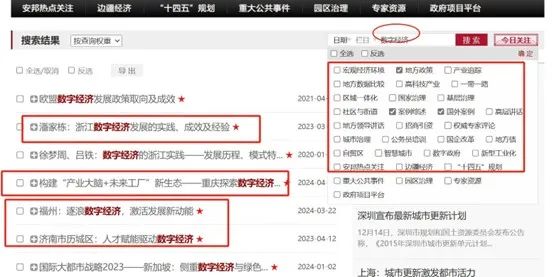
ChatGPT:


专:智库的专业视角,团队服务
通过专业的团队对政府大数据信息库进行维护、开发,政府库能够提供专业的政策解读、专题报告及信息参要等服务;
同时还提供信息顾问、战略顾问等个性化的咨询服务,根据用户的具体需求,提供定制化的解决方案。


丰:宏观全面,丰富多样
与其他专精研究团队相比,安邦政府大数据信息库涵盖了广泛的政策领域,包括但不限于宏观经济、城市治理、产业追踪、地方政策及实践等多个方面。
无论是政府机构、企业组织,还是学术研究人员,都可以在该数据库中找到所需的政策信息和分析工具。
安邦政府大数据库新功能-热点风口数据库

结语
当前复杂多变的政策环境中,在安邦政府大数据信息库,用户能够更快地找到所需要的信息,更好地理解和应对政策变化,从而做出更科学、合理的决策。
安邦30年如一日,基于公开信源研究,信息服务能给出低成本高效益的效果,“精细专丰”,在政策分析领域独树一帜。
本文部分图片来自网络,侵权删


